Généralités
Recherche exacte
Utilisez les guillemets » » pour effectuer une recherche exacte qui limitera les résultats aux termes dans l’ordre dans lequel ils se présentent dans la requête.
Par exemple, la recherche Global warming ramène plus de résultats que la recherche « Global warming » car Global et warming ne sont pas forcément dans le même champ ; la recherche « Global warming » limite la requête à la présence juxtaposée des deux termes.
Opérateur booléens
AND, OR et NOT ou ET, OU et SAUF (toujours en majuscules), éventuellement avec des parenthèses pour des regroupements ;
- entre 2 termes, le AND est implicite
Masques
- Le signe ? remplace 1 caractère
- sauf en fin de mot où il est interprété comme le signe de ponctuation
- Le signe * remplace plusieurs caractères
L’utilisation de masques dans les recherches exactes n’est pas autorisé.
Attention : dans les données CDI, l’usage des masques n’est pas forcément la meilleure solution, puisque certaines des fonctionnalités spécifiques décrites ci-dessous ne s’appliquent pas aux recherches incluant un masque ? ou * (notamment les fonctionnalités qui s’appliquent à toutes les langues comme la racinisation, l’identification des synonymes ou la normalisation orthographique).
Par exemple, dans CDI, la recherche sur Archaeology ramènera plus de résultats que la recherche sur Archaeolog* car la fonctionnalité de normalisation orthographique permettra d’identifier aussi les résultats qui contiennent Archeology.
Fonctionnalités de langue : environnement multilingue
En plus de gérer le standard Unicode et ainsi permettre les recherches dans divers systèmes d’écriture, Primo propose des fonctionnalités étendues qui s’appliquent à plusieurs langues, dont l’anglais, le français, l’allemand, le néerlandais, l’italien, le danois, l’espagnol…
Segmentation (tokenization)
Le processus consiste à identifier la plus petite unité lexicale (token) interrogeable dans CDI, et est intéressant notamment dans le cas des langues où les mots ne sont pas séparés par l’espace (par exemple, chinois, japonais…).
Décomposition (decompounding)
Le processus de décomposition permet d’identifier les différents composants d’un mot composé. Cela permet à l’utilisateur qui lance une requête sur les composants de récupérer aussi des résultats où les composants forment un mot composé.
Par exemple, la recherche sur les mots allemands Abwasser-Anlagen (stations d’épuration) ramène des résultats qui contiennent le mot composé Abwasserbehandlungsanlage.
Racinisation/Lemmatisation (stemming/lemmatization)
La racinisation identifie la racine, ou radical, du mot, une fois supprimés ses suffixes ou préfixes.
Par exemple, le radical fish pour fisher, fishing, fished…
La lemmatisation identifie la forme non fléchie (en genre, nombre, mode…)
Par exemple, petit pour petits, petite, petits…
Le processus est adapté à la langue.
Exemples :
- une recherche sur le mot anglais ponies ramènera aussi des notices contenant le mot pony au singulier.
- une recherche sur le mot français maisons ramène aussi des notices contenant le mot maison au singulier.
Normalisation des caractères
Les caractères avec diacritiques sont normalisés au caractère sans diacritique.
Le processus est généralement le même pour toutes les langues, mais des mappings spécifiques peuvent exister.
Exemples :
- résume / resume en français
- México / Mexico en espagnol
- l’umlaut allemand est géré pour permettre la recherche sur la lettre avec le diacritique (ä) comme sur la forme « ae » ou « a ».
Translittération
Permet la recherche dans une forme d’écriture et le retour de résultats dans une autre forme d’écriture.
Traitement de l’élision
Gestion des voyelles effacées, notamment pour le français et l’italien.
Exemple :
- la recherche sur arbre identifiera bien les résultats contenant l’arbre
Synonymes et normalisation orthographique
Mappings simples spécifiques à chaque langue.
Par exemple, en anglais, theatre et theater.
En plus, le signe & est transposé en mot pour chaque langue (et, and, und…)
Nombres : le nombre en lettres est ajouté à une requête sur un nombre en chiffre (neuf est ajouté à 9 ; ninth est ajouté à 9th).
Pour les termes les plus couramment mal orthographiés, le terme correct est ajouté à la requête.
Lors de recherches avec des termes avec un trait d’union, la recherche portera aussi sur la variante sans trait d’union (chat-room -> résultats chat room et chatroom). Liste des termes concernés : Supported Compound Words
Pour une liste des synonymes concernés : anglais ; allemand
Mots vides
Primo VE maintient une liste propre à chaque langue.
Pour conserver des mots vides dans une requête, utiliser les guillemets : « man of the world »
Pour une liste des mots vides concernés : français ; anglais ; allemand ; espagnol ; italien
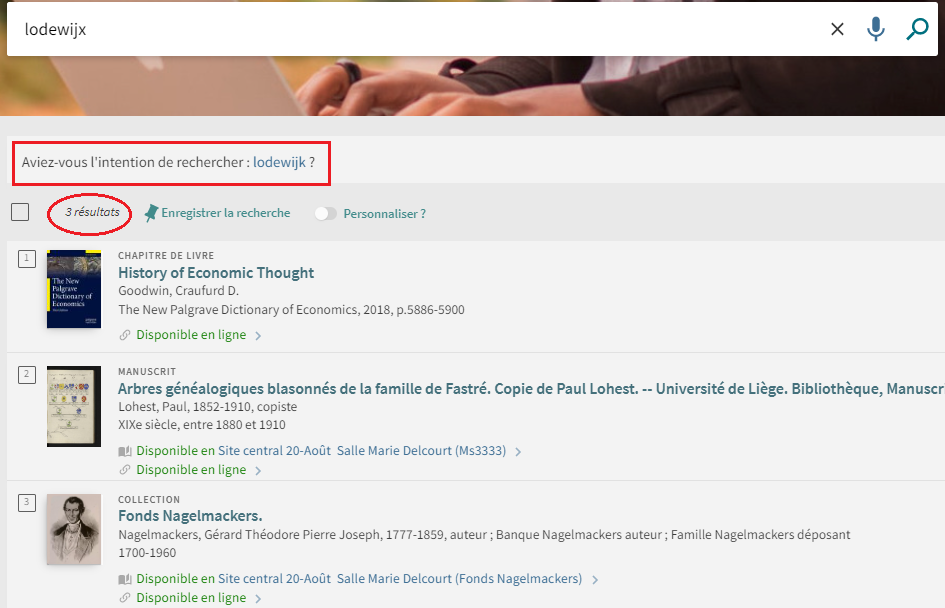
Did you mean ?
Les suggestions (did you mean ?) permettent d’améliorer la requête en corrigeant les erreurs typographiques et les fautes d’orthographe courantes afin de renvoyer à l’usager le résultat de recherche attendu.
Les suggestions sont fournies lorsque le résultat de recherche est inférieur à 15.
Fonctionnalités spécifiques aux données du Central Discovery Index CDI
Recherche exacte
Les guillemets sont en général utilisés lorsque la requête inclut plusieurs mots, mais ils peuvent également être utilisés pour favoriser la recherche mot à mot (verbatim search).
Par exemple, une recherche sur le terme ATLA ramène les résultats comprenant Atlas, ce qui génère beaucoup de bruit dans les premières pages de résultats.
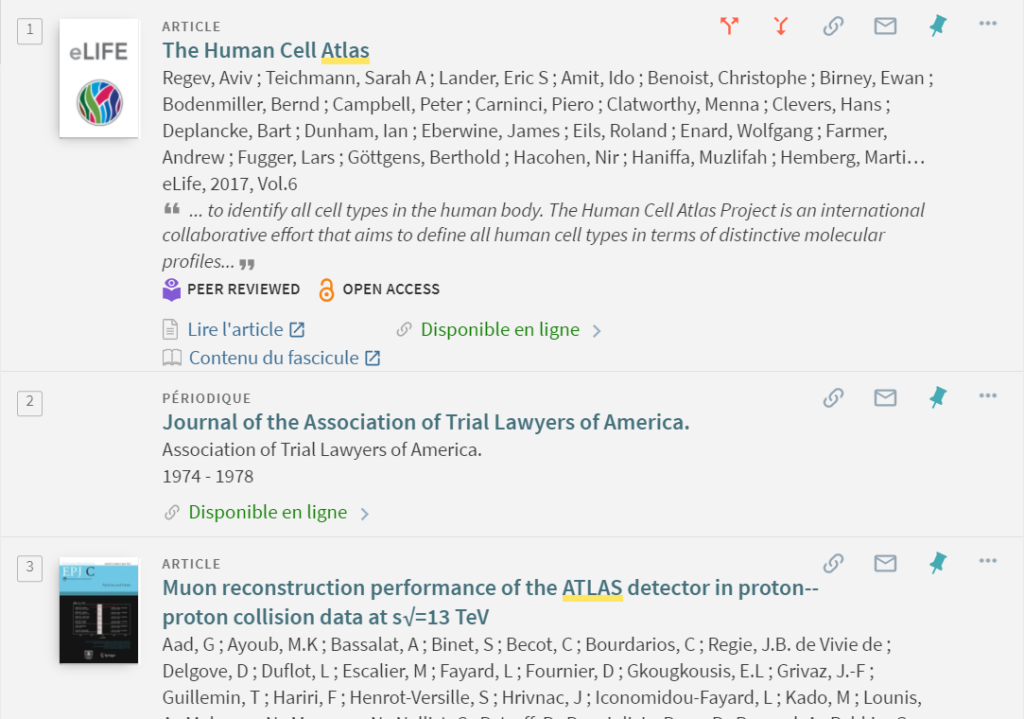
Pour limiter des résultats non souhaités, on peut favoriser la recherche mot à mot en utilisant les guillemets : « ATLA »

Étendre la recherche aux variantes du terme de recherche : Query expansion
Pour les données CDI, Primo étend la recherche aux formes préférées identifiées dans les référentiels LCSH ou MeSH. Ainsi, si l’utilisateur utilise le terme de recherche Hyperkinetic syndrome, la fonctionnalité Query expansion étendra la recherche à Attention-deficit hyperactivity disorder parce que Attention-deficit hyperactivity disorder est la forme préférée du terme Hyperkinetic syndrome dans le référentiel LCSH.
Les termes de recherche ainsi étendus peuvent se retrouver dans les métadonnées de la ressource, comme dans le texte intégral.
L’expansion ne fonctionne pas dans les cas suivants :
- lorsque l’utilisateur effectue une recherche de type « phrase » en utilisant les guillemets
- « Hyperkinetic syndrome »
- si l’utilisateur introduit une requête trop longue
Attention : ne pas confondre cette fonctionnalité, qui s’applique quel que soit le champ où le terme est trouvé, avec l’exploitation des référentiels (fichiers d’autorité) qui ne s’applique qu’aux données locales et limite la recherche à la zone qui contient la forme préférée.
Recherche mot à mot (verbatim search)
Toutes les fonctionnalités énoncées ci-dessus permettent à l’utilisateur d’obtenir des résultats lorsque les termes de la requête et les termes indexés sont équivalents, c’est-à-dire un synonyme, un processus de racinisation… Ces processus, qui conduisent à une augmentation du nombre de résultats, s’ils permettent à l’utilisateur d’élargir sa recherche, peuvent aussi amener des résultats non pertinents, ou moins pertinents, et ainsi réduire la précision.
Pour cela, CDI inclut un boost de la correspondance mot à mot. Ainsi, si la recherche porte sur le terme theatres, les notices qui contiennent theatres auront plus de points dans le score de pertinence que les notices qui contiennent theatre ou theaters.
Pour exclure des résultats trop éloignés de la requête initiale, l’utilisateur peut aussi forcer la correspondance mot à mot en utilisant les guillemets : « theatres »
Pour en savoir plus :